Preprint is out! eyeballvul: a future-proof benchmark for vulnerability detection in the wild
A previous blog post introduced the eyeballvul vulnerability detection benchmark. The preprint on this work is now out (arxiv)! This post closely follows the Twitter thread where I announced this work.
I create a benchmark to evaluate the vulnerability detection capabilities of long-context models on entire codebases, containing over 24,000 vulnerabilities, then evaluate 7 leading long-context models on it.
eyeballvul has a few unique strengths compared to existing benchmarks and datasets:
- real world vulnerabilities: sourced from a large number of CVEs in open-source repositories;
- realistic detection setting: directly tests a likely way that vulnerability detection could end up being deployed in practice (contrary to many previous classification-type datasets);
- large size: over 6,000 revisions and 24,000 vulnerabilities, over 50GB in total size;
- diversity: no restriction to a small set of programming languages;
- future-proof: updated weekly from the stream of published CVEs, alleviating training data contamination concerns; far from saturation.
It is fully open-source (code and data). Its main weakness is the reliance on an LLM scorer, coupled with the frequent lack of specificity in CVE descriptions.
The benchmark consists of a list of revisions (commit hashes) in 5,000+ open-source repositories, with the known vulnerabilities at each revision as ground truth. Models are asked to list vulnerabilities after reading the code, and the LLM scorer compares the two lists of vulns.
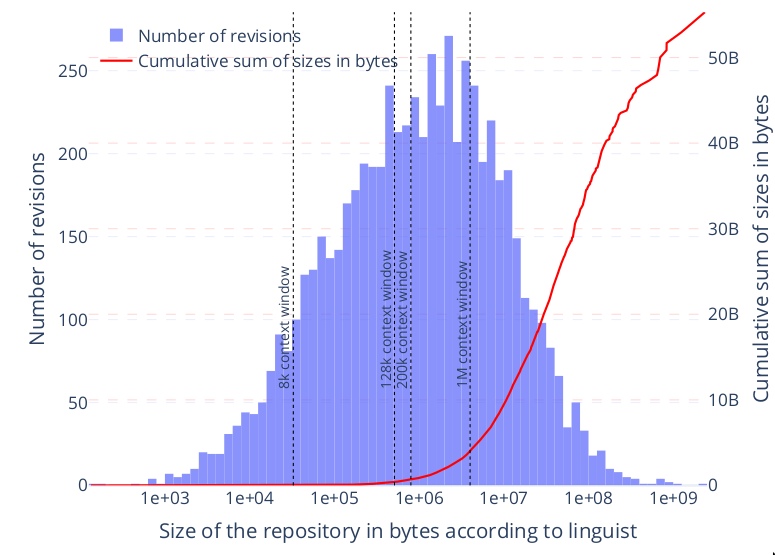
The main results are below:
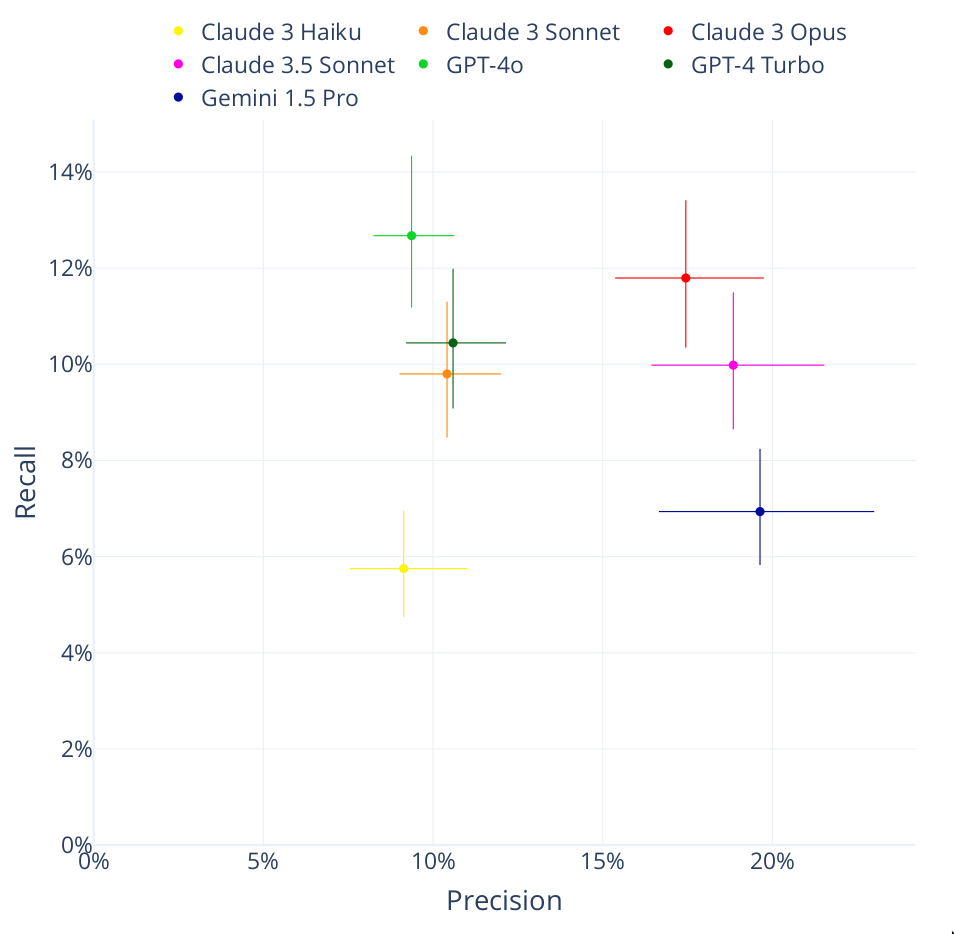
Overall, performance remains low. But I’ve only tested the simplest possible tooling, and expect that big improvements could come from e.g. spawning agents to investigate each lead in more detail, giving them access to debugging and other tools… Similar to how Google’s Project Zero increased performance on CYBERSECEVAL 2 in Project Naptime.
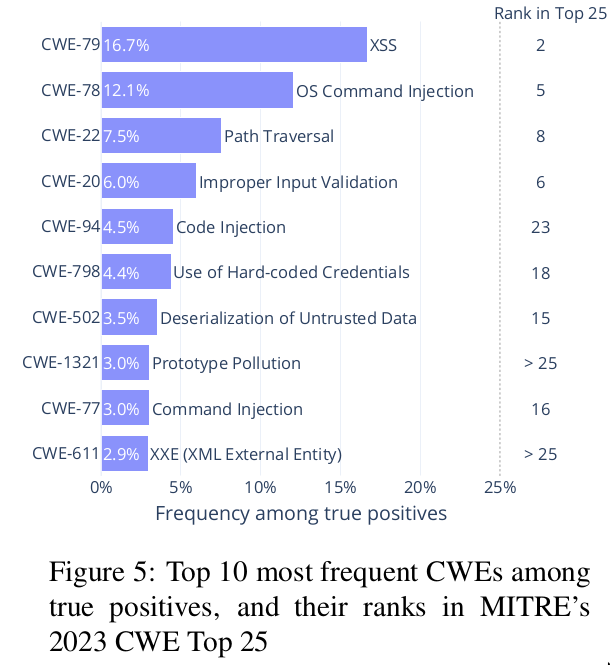
By comparing the most frequent CWEs in true positives to MITRE’s Top 25 list, I conclude that models are best at finding superficial vulnerabilities such as the various injection vulnerabilities, path traversal, hard-coded credentials… Which makes sense, as models are only given a single pass at reading a codebase. But while superficial, these vulnerabilities tend to be severe, so finding them is useful!
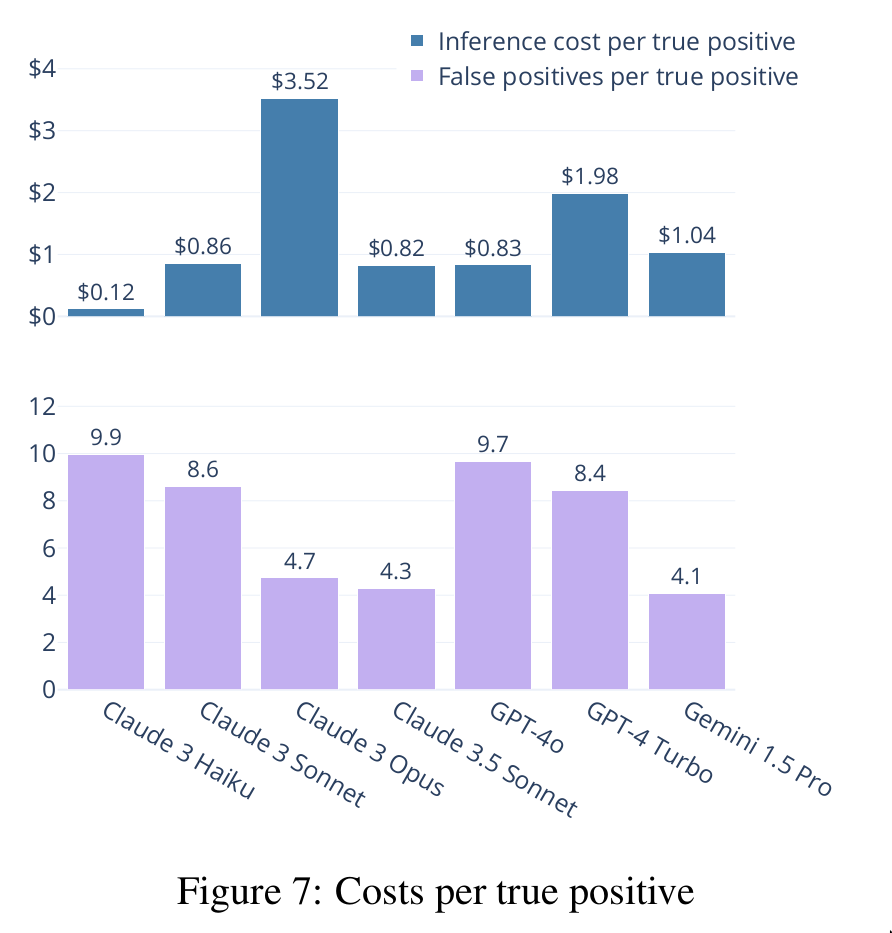
I estimate that false positives are the main contributor to cost with my tooling. Using rough guesses (10 minutes lost per false positive at $100/h), false positive costs range from $68/TP (true positive) to $165/TP, while the highest inference cost is $3.52/TP. Claude 3.5 Sonnet and Gemini 1.5 Pro stand out from the other models, with simultaneously low inference costs and number of false positives per true positive.
I go through 100 random CVEs and rate them from 1/5 (crucial lack of specificity, too difficult to compare) to 5/5 (enough specificity to easily compare). I find that around 63-70% of CVEs are usable (rated 4+ or 3+).
In terms of impact, I argue that AI vulnerability detection in source code should empower defenders over attackers, especially in the absence of sudden jumps in capabilities (which this benchmark should help to prevent), and especially if a few things happened:
- an initiative such as OSS-Fuzz (Google running fuzzing on hundreds of security critical open-source repositories for free) being launched once models are good enough;
- AI labs spending inference compute of their SOTA models on this project prior to release (as far as I know, this would be the first example of a useful external task that they should spend compute on pre-release).
Another goal of this benchmark is to introduce the above two asks to the relevant decision makers, and inform when they should start executing on them.