Cheaply detecting changes in LLM APIs
Links: [X thread] [LT paper] [B3IT paper]
LLM APIs are opaque black boxes, even for open-weight models. Can we continuously monitor them for changes?
We published two papers on the topic:
- Log Probability Tracking of LLM APIs (ICLR 2026)
- Token-Efficient Change Detection in LLM APIs (ICML 2026)
The first paper was a joint work with my advisors Erwan Le Merrer, François Taïani and Gilles Tredan, and the second paper was additionally a collaboration with Clément Lalanne and Jean-Michel Loubes from IMT Toulouse.
These are two methods designed to be extremely cheap to run: they only request a single token of output at a time from APIs, with very short prompts.
The first method, Logprob Tracking (LT), shows that when logprobs are returned by the API provider, we can use this for extremely sensitive and cost-effective change detection.
The second method, Black-Box Border Input Tracking (B3IT), extends this to the more common case of fully black-box APIs which don’t return logprobs.
Logprob Tracking (LT)
This paper shows that when API providers support returning logprobs, these can be used to monitor for changes at extremely low cost, e.g. $0.14/year for hourly sampling of GPT-4.1. It turns out that logprobs are non-deterministic due to non-determinism of inference on GPUs, but we can still basically track logprob averages and this works great. This is also very sensitive to small changes.
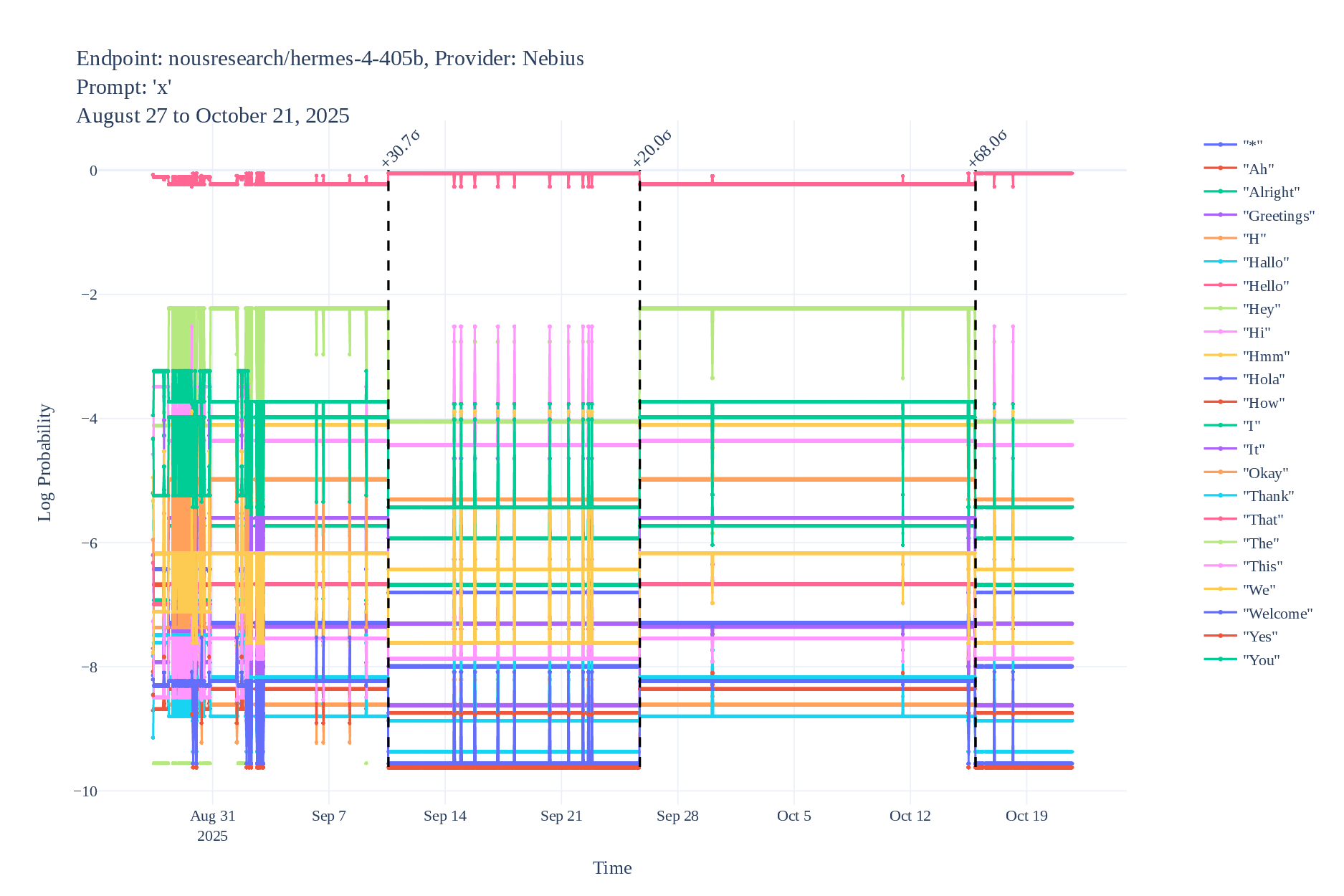
Some example logprob time series (with detected changes):
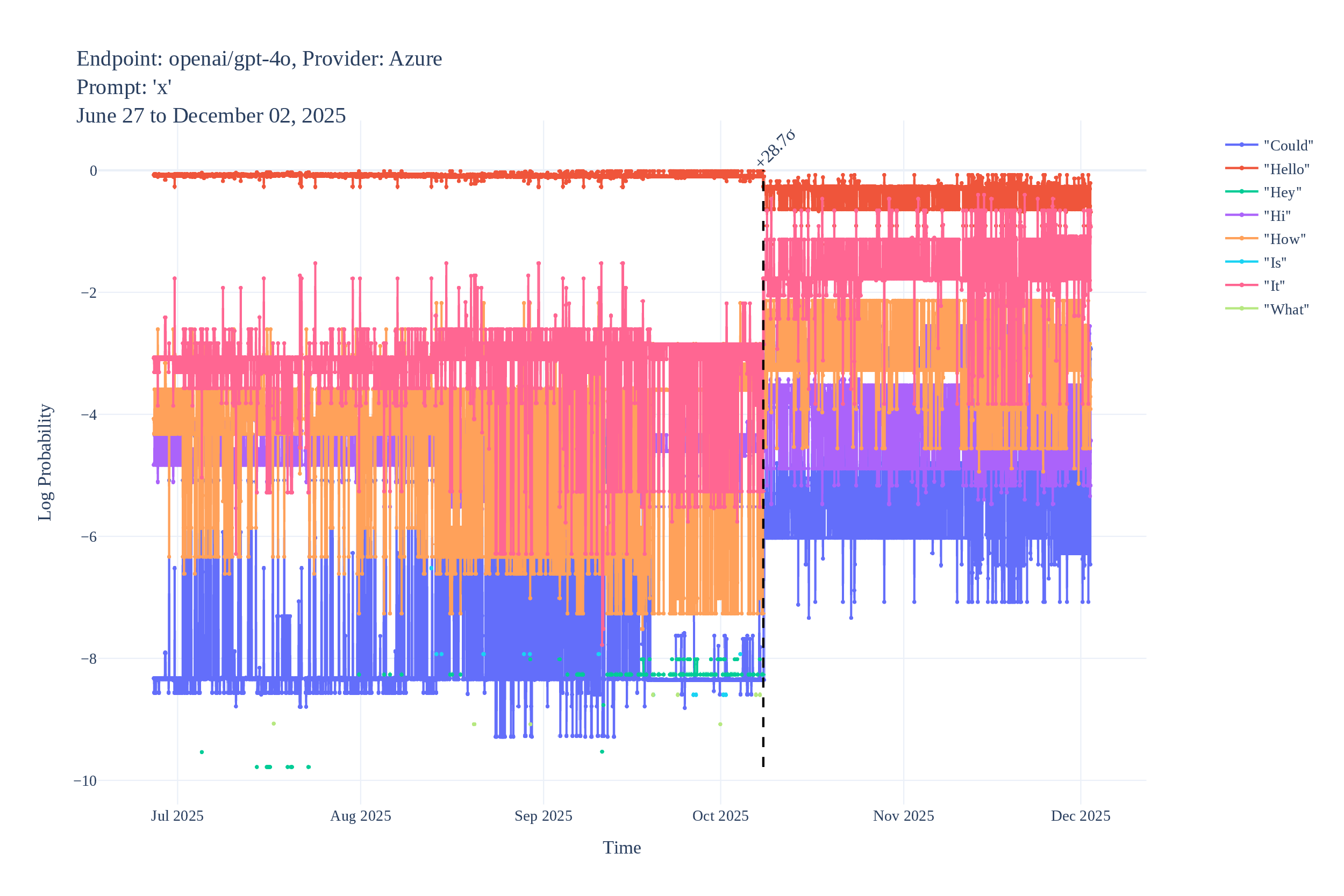
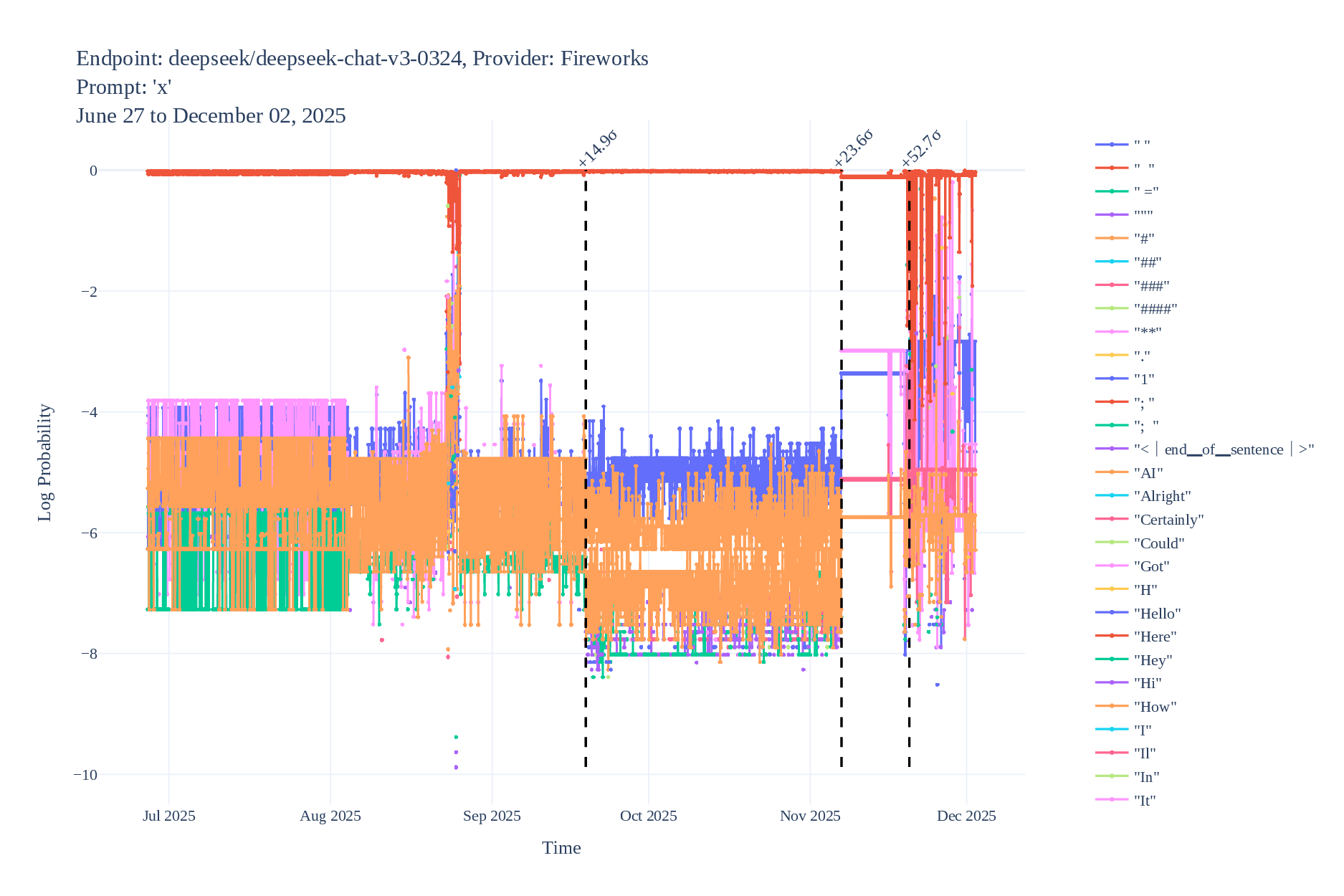
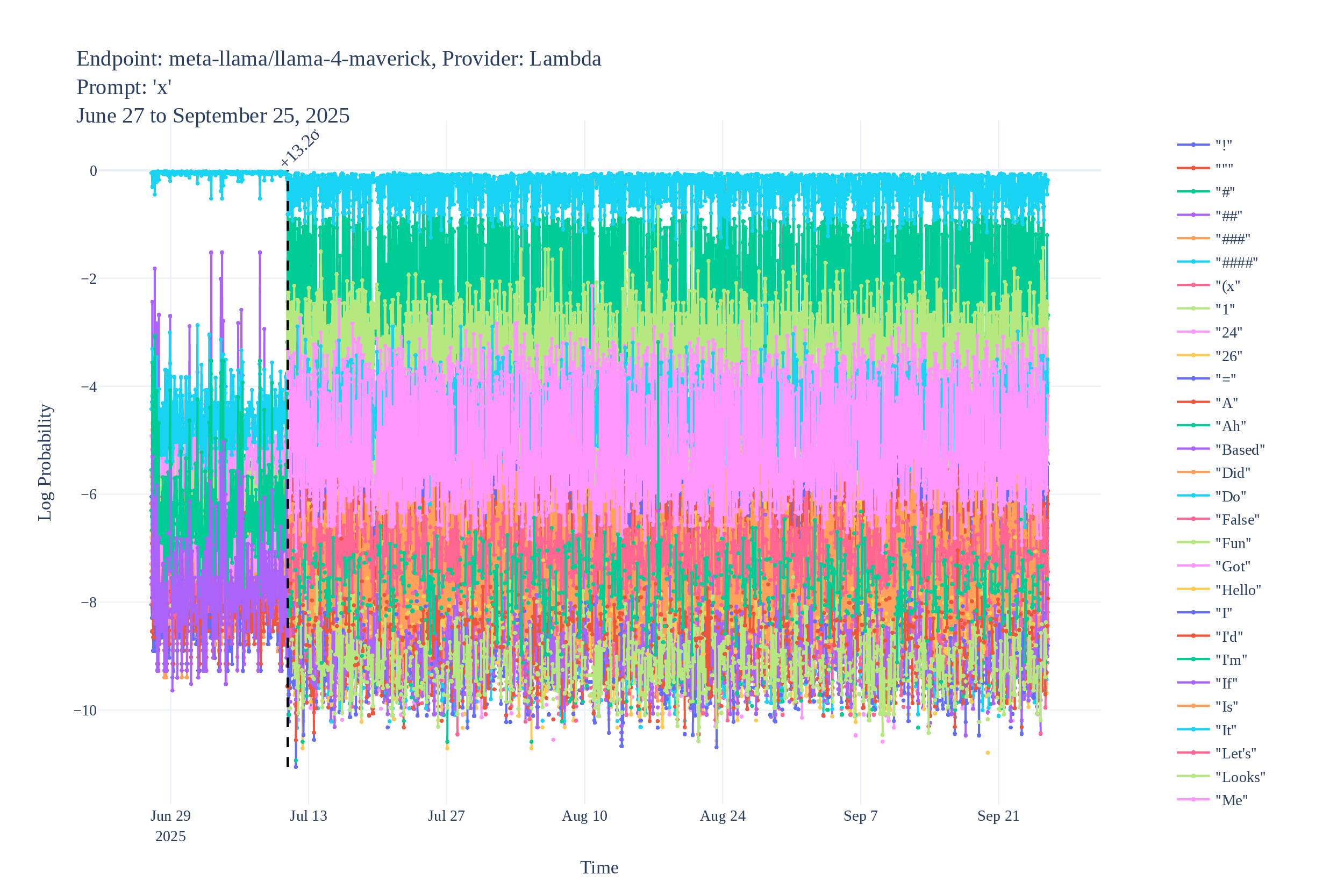
Black-Box Border Input Tracking (B3IT)
The second paper extends LT this to the setting where logprobs are not available (pure black-box). The idea is to identify Border Inputs, for which sampling at $T=0$ doesn’t always give the same output (again, looking only at the first token of output). It turns out they can easily be found just from black-box sampling, trying thousands of short inputs and keeping the border inputs. Then, being at $T=0$ makes any change in the model likely to move this border and result in a notably different output distribution when we sample each border input a few times. We prove this by analyzing the model’s Jacobian and the Fisher information of the output distribution in low-temperature regimes, specifically leveraging the Local Asymptotic Normality framework.
This is a bit more expensive than Logprob Tracking, but applies to basically any black-box LLM API, and still outperforms existing methods by wide margins, as shown in this Pareto plot:
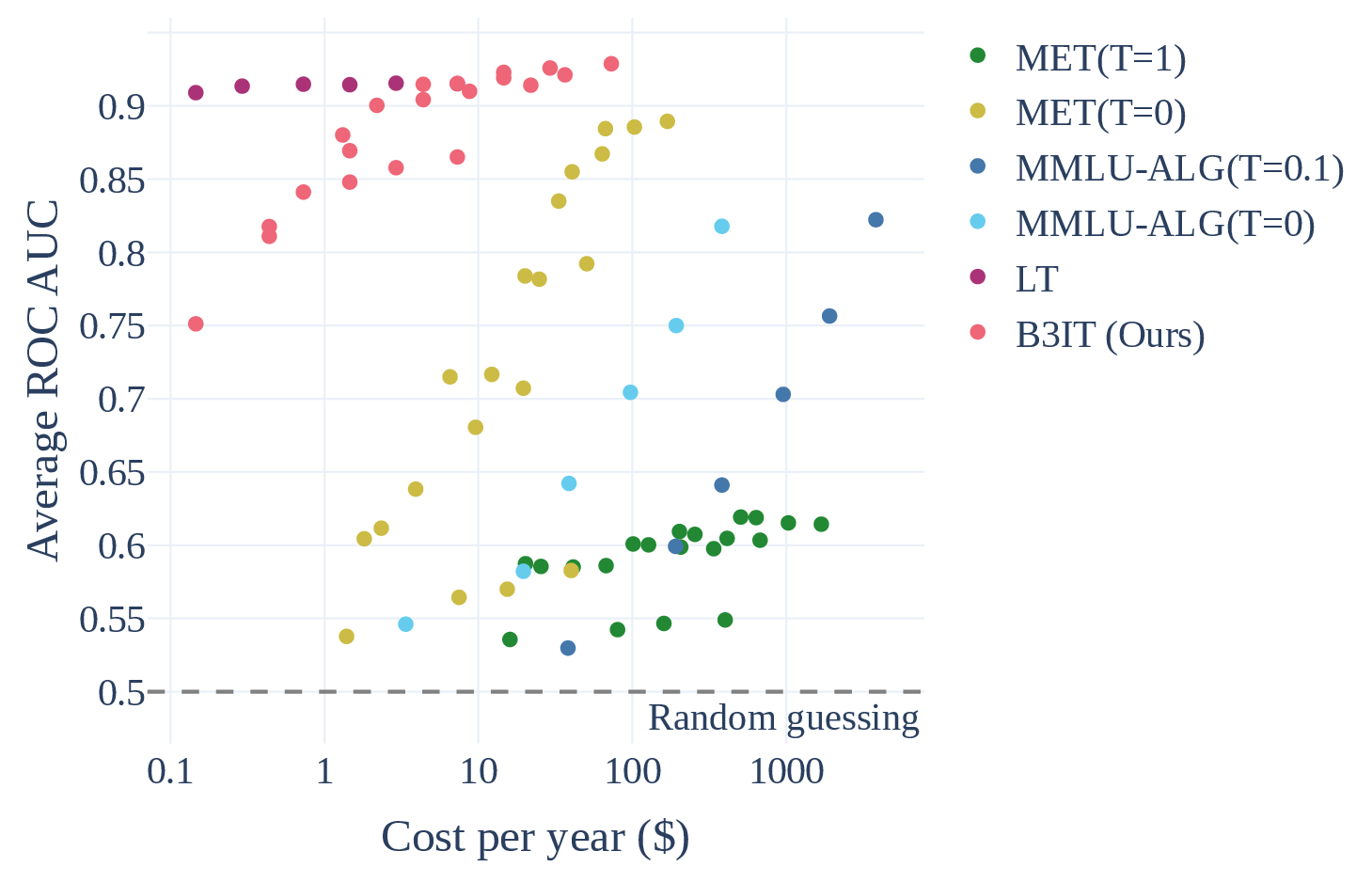
Results
Since these methods are cheap, we actually ran them, and found multiple instances of undisclosed changes in LLM APIs. Logprob Tracking (each point is an identified change with high confidence):
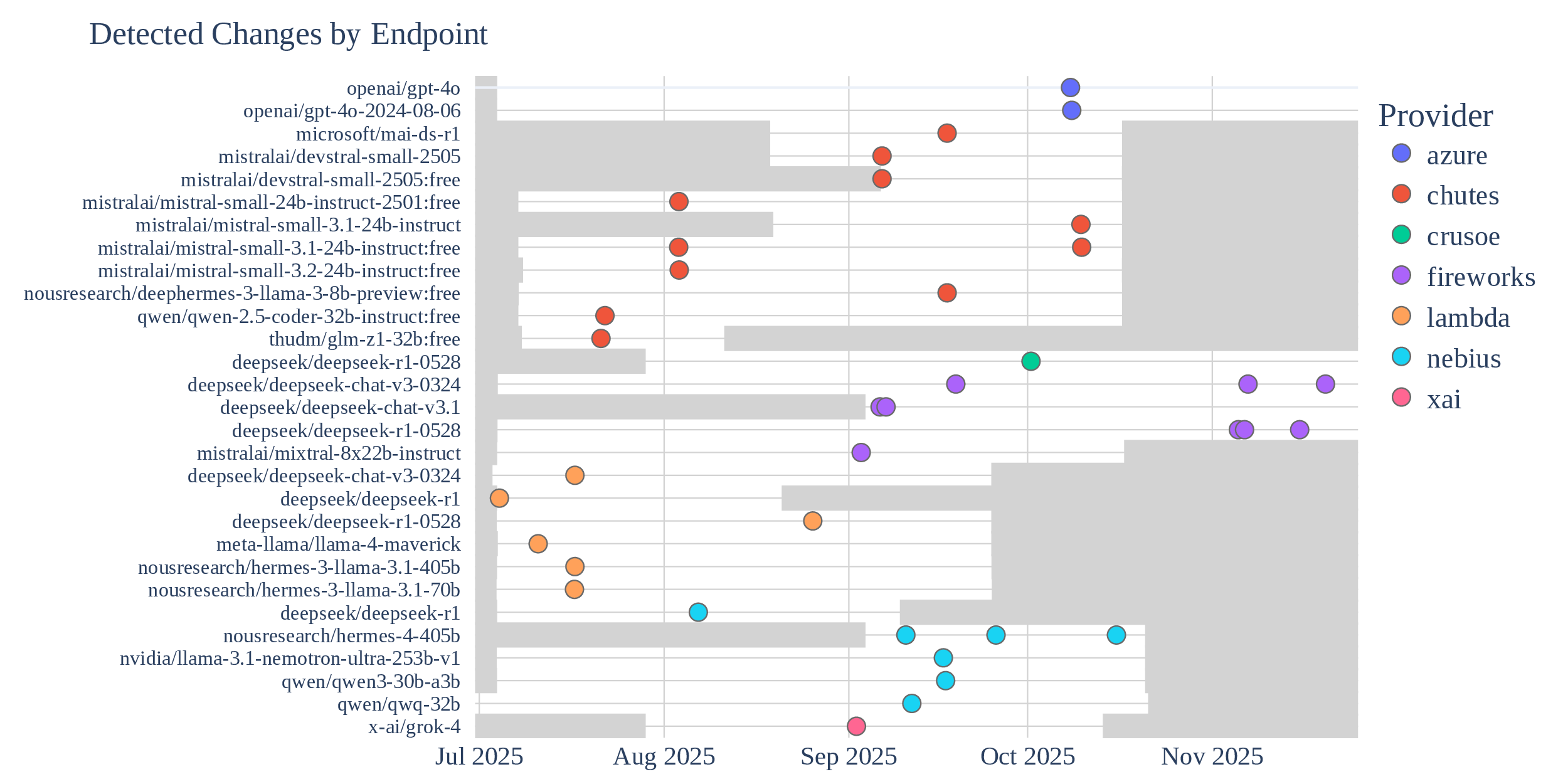
We also found instances of undisclosed changes with B3IT.
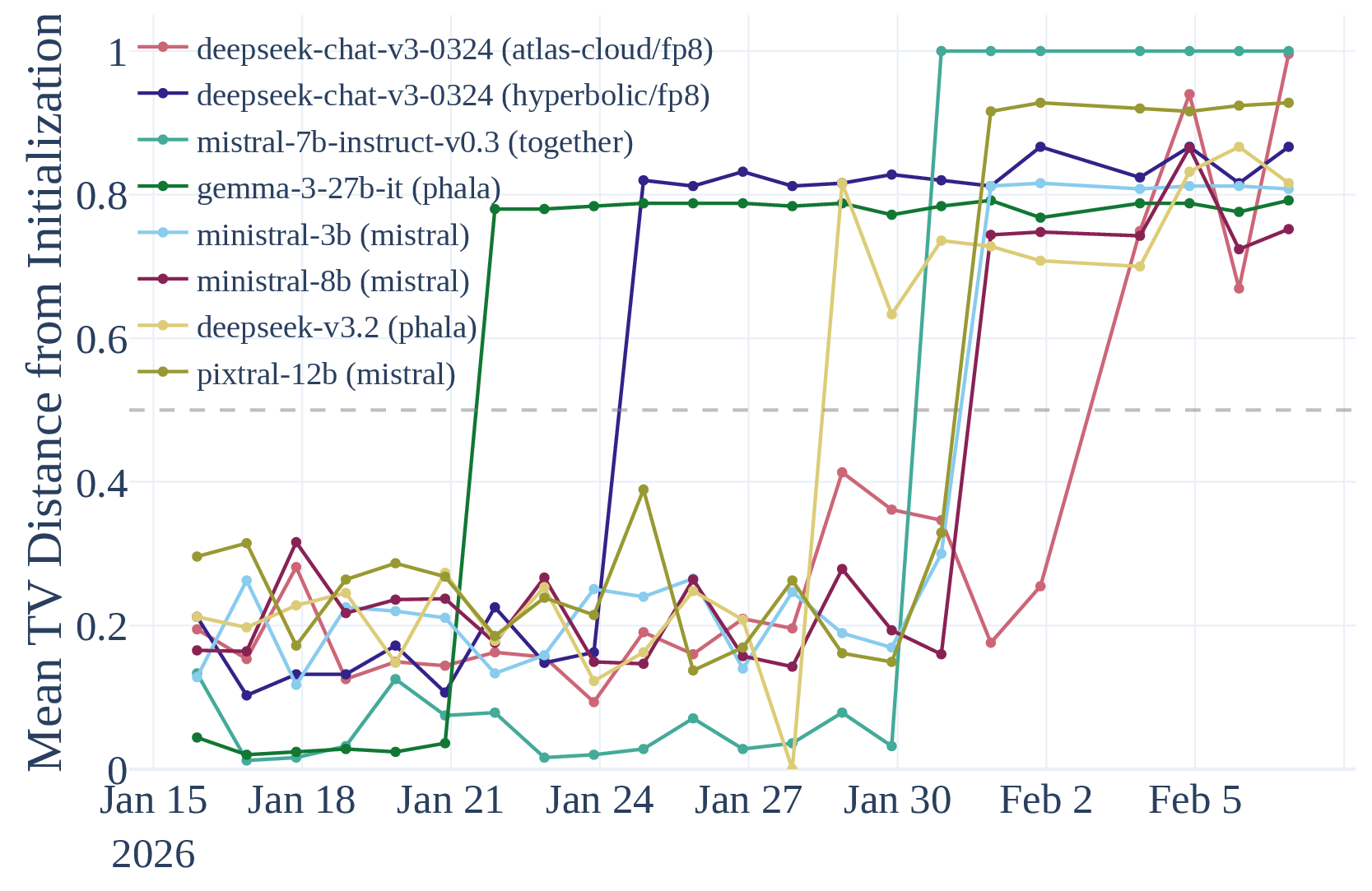
Actually, one of them was disclosed: did you know that if you had something running on “Mistral-7B-Instruct-v0.3” from Together AI, they silently (though with a public announcement) redirected it to the entirely different Ministral-3-14B-Instruct-2512 in January?
Conclusion
LLM API stability is important for the reliability of downstream applications, for the reproducibility of research and for initial audits to remain relevant.
Small changes are fine but they should be disclosed, so that end users can verify that their use cases weren’t affected.
LLM API providers could support a more secure and transparent ML supply chain by:
- supporting output logprobs (especially for open-weight models and non-frontier models, where model stealing isn’t a threat);
- always disclosing changes to models or infra.
We are still monitoring a good number of APIs, and a website is in progress to share live results, stay tuned…
Appendix
A mystery for you
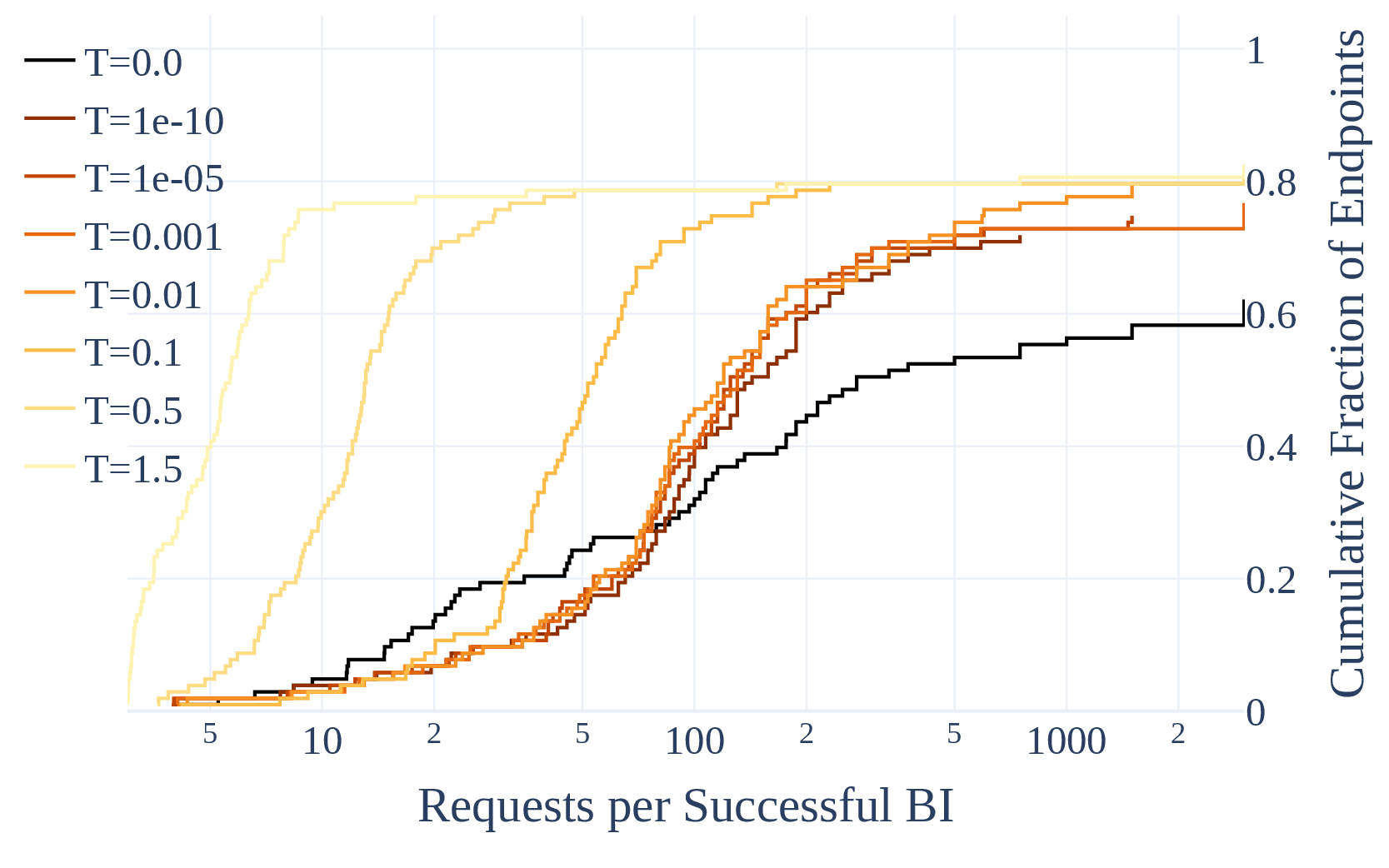
As part of building B3IT, we found an unexpected result that we’re not sure how to explain, and may have implications for people using $T=0$. This plot shows the number of requests necessary to find a Border Input (i.e. sampling each input 3 times, an input that doesn’t always give the same token in first position). As $T \to 0$, the curves are approaching a limit… But at $T = 0$, the curve is different from that limit. At least for border inputs, $T = 0$ and $T \simeq 0$ behave differently for many providers. There are certainly some hard-coded behaviors at $T=0$, but there shouldn’t be such a jump between $T \simeq 0$ and $T = 0$.
This plot covers 93 API endpoints representing 64 unique models and 38 providers, with 3,000 queries (3 $\times$ 1,000 inputs) per endpoint, so I think it’s legit.